

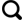


1 引 言
土壤作为人们赖以生存的重要载体,是农作物生产的重要保障,土壤质量的好坏直接影响着粮食的安全和人们的健康。随着城市化的快速发展,城市废弃物、工业污染等所带来的重金属排放极大地影响着土壤的环境,对土壤质量及其功能有着严重的影响。因此对土壤中重金属含量进行大范围、高效率、高精度的快速监测成为了一个急需解决的问题。传统的检测手段以现场采样、实验室检测分析法为主,其监测精度高,但成本昂贵、耗时长、获得的信息有限等缺点,并不能很好地解决大面积土壤重金属含量的实时监测问题。高光谱遥感技术快速、高效、准确的特点使得它成为目前土壤重金属研究的有效途径,在近年来受到了不少国内外学者的关注[1]。
偏最小二乘回归法(Partial Least Squares Regression,PLSR)[2-3]、多元线性回归、支持向量机[4]等线性模型被广泛地用于重金属含量反演研究。如Kooistra等[5]使用PLSR模型对莱茵河周围的土壤重金属进行反演取得了较好的结果。张明月等[6]提出一种反向光谱吸收积分的光谱特征参数,使用PLSR模型对东北黑土区中的铬元素含量进行了反演研究,研究表明反向光谱仪吸收积分处理对反演模型的精度和稳定性有一个较好的提高。郭学飞等[7]对北京市土壤样本光谱反射率数据使用多种数学变换,采用多元线性回归和偏最小二乘回归方法进行重金属元素反演,结果表明基于光谱二阶微分的多元线性回归模型(SD-MLR)的稳定性和精度最高。Stazi等[8]使用支持向量机的方法进行建模从而较好地反演出调查区中土壤砷的含量。
因此,本文使用非线性特征提取方法,针对土壤中重金属光谱反射率较低、光谱数据冗余的问题,以广东省连州地区土壤重金属含量为对象,开展高光谱特征提取算法的土壤重金属高光谱定量反演模型研究。提出了粒子群优化BP神经网络(PSO-BPNN)、遗传算法优化BP神经网络(GA-BPNN)反演模型,将两个优化模型与单一的BP神经网络及偏最小二乘进行比较,同时分析非线性模型与线性模型对土壤光谱数据特征提取问题,并针对不同光谱预处理对于光谱特征提取效果的差异进行了讨论,以寻求最佳的土壤重金属反演模型。
2 数据与研究区
2.1 研究区概况
连州市(112°07′~112°47′E,24°37′~25°12′N)位于广东省清远市,地形以山地为主,平原较少,属于典型的山区。全市土地面积为26.69万hm2,耕地面积仅占16.87%[11]。连州市地处亚热带季风气候区域,全年受季风气候影响较大,气候条件优良,水源充足,使得农业化发展较快,从而在一定程度上造成了局部地区农业过度施用化肥。同时,非金属矿开采所带来的废弃物排放,造成地区内有大量重金属累积于地表,因此土壤重金属污染成为重要的研究课题。
2.2 样品采集及处理
在研究区共选取了50个采样点,定点采集距耕地表面0~20 cm深度的土壤,土壤样品约为200 g,并用深色密封袋进行封装。在采集的过程中使用GPS仪记录其经纬度。将土壤样本运回之后,在通风的环境下自然风干,并将其进行研磨、去杂质等处理,使用60目的尼龙筛进行过筛,并用密封袋进行样本封装。将得到的样本分为两份,分别用于土壤光谱数据的采集和模型反演预测。
图1
2.3 土壤光谱测定
采用四酸消解法电感耦合等离子体发射光谱质谱法测定土壤重金属含量,该方法监测精密度好、灵敏度高、抗干扰性强[12]。将已经研磨并且经过筛选之后的土壤样本,每份样品称取试样(0.25 g)于试管中,再用浓硝酸、高氯酸和高氯酸消解,之后将溶液于185 ℃蒸发至近干,去除残留的氢氟酸。残液用盐酸稀释并定容,再用等离子体发射光谱与等离子体质谱进行分析得到土壤反射光谱。在本次实验中土壤样品光谱反射率数据的采集使用的是PSR+3 500便携式地物光谱仪,该光谱仪覆盖的光谱范围为350~2 500 nm,对每个样品进行10次测量,并取这10次测量的平均值作为目标样本的光谱反射率结果。
3 研究方法
3.1 光谱预处理
由于对土壤进行光谱数据采集、获取的过程中,容易产生影响光谱反射率曲线的噪声,这些噪声可能来自于仪器、环境、人为操作等因素[13],其会对光谱预测模型产生极大的影响,因此在使用模型进行预测之前需要对原始光谱数据进行预处理。为降低噪声对于建模的影响,将测得的土壤样本光谱在350~399 nm、2 450~2 500 nm噪声较大的波段进行剔除,保留重金属反演的主要波段400~2 449 nm用于建模分析。
研究使用Savitzky-Golay方法对光谱曲线进行平滑去噪声处理,能够较好地去除土壤背景噪声的同时保留原始数据的真实性。同时,光谱数据波段之间重叠性较大,自相关性强,为了突出土壤光谱的特征差异,从而更好地提高模型的预测能力[14],需要对光谱曲线进行一系列数学变换处理。因此使用多元散射校正(MSC)、 标准正态变量校正(SNV)、一阶微分(FD)、对数一阶微分(AT-FD)、多元散射校正一阶微分(MSC-FD)、标准正态变量校正一阶微分(SNV-FD)6种变换对光谱信息进行增强处理,突出光谱特征。
3.2 样本划分
为保证模型精度,需要在模型训练之前将样本进行一个简单的划分,一组用于模型的训练使用,即训练集,另一组用于模型预测结果精度检验使用,即验证集。为使训练样本空间分布均匀,因此对50个土壤光谱样本进行预处理,并对样本数据采用箱线图进行异常值的剔除,再按照3∶1的比例,采用K-S(Kennard-Stone)算法划分训练样本与验证样本。样本划分结果如表1所示。
表1 样本划分
Table 1
| 元素 | 样本集 | 样本数目/个 | 最小值 /(ug/g) | 最大值 /(ug/g) | 平均值 /(ug/g) | 标准差 /(ug/g) |
|---|---|---|---|---|---|---|
| Cr | 训练集 | 35 | 13.20 | 179.50 | 91.90 | 41.79 |
| 预测集 | 15 | 26.00 | 156.00 | 72.99 | 32.91 | |
| Cu | 训练集 | 35 | 10.25 | 66.10 | 34.16 | 15.20 |
| 预测集 | 14 | 10.50 | 55.80 | 26.71 | 10.29 |
3.3 模型选择
3.3.1 偏最小二乘回归模型
偏最小二乘回归模型(Partial Least Squaresreg Ression,PLSR)针对两组多重相关变量之间的相互依赖关系,用一组自变量去预测另一组因变量。模型中包含了主成分、相关性和多元线性回归3种算法的组合,适合于自变量中存在多重相关性的情况,是目前土壤中重金属含量反演最常使用的模型之一。
3.3.2 BP神经网络
BP神经网络(Back Propagation Neural Network,BPNN)由输入层、隐含层和输出层组成的前向网络,采用输出结果前向传播,误差反向传播的方式进行训练。对于N个输入,经过隐含层之后,采用梯度下降法,将会在输出层中得到M个输出,即可得到误差最小的非线性网络转换结果。
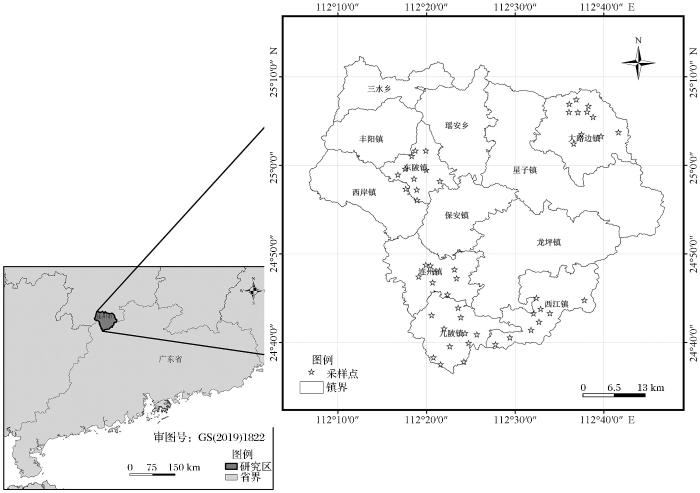
3.3.3 PSO-BPNN和GA-BPNN反演模型
BP神经网络在进行预测的过程中初始权重和阈值的选取时,局部收敛极小点的出现会使得预测精度的降低。因此本文采用粒子群(Particle Swarm Optimization, PSO)优化BP神经网络的算法,使得BPNN的初始权重和阈值得到优化,从而解决会出现局部收敛极小点的问题,提高预测的精度。
在确定BP 神经网络的各层结构之后,初始化粒子的速度、位置、惯性因子等参数,更新粒子的速度和位置,再计算粒子的适应度值F(i)、个体极值
遗传算法(Genetic Algorithm,GA)通过优化BP神经网络的初始权重和阈值,从而达到提高预测精度的效果。首先确定神经网络结构,即可确定遗传算法的优化参数个数,得到初始的种群。种群中每个个体都有其在网络中的权重和阈值,再通过计算得到个体的适应度值,选择适应度高的染色体进行复制、交叉以及变异等操作,找出适应度最高的个体。再将得到的最优个体的初始权重和阈值对神经网络进行相应的赋值,网络的训练精度将会提高。BPNN模型的适应度函数选用均方根误差(MSE)作为核函数进行计算:
其中:
图2
4 结果分析
4.1 相关性分析
由于得到的光谱数据中数据维数较大,产生的数据冗余会影响模型预测的精度。相关性分析有利于将土壤重金属含量与其光谱反射率之间的相关程度进行表达[15],提取出相关性较大特征光谱波段,以便后续土壤重金属含量反演研究。本次实验将预处理之后的Cu、Cr两种土壤重金属元素光谱数据与重金属含量进行Pearson相关分析,以极显著相关P=0.01作为特征选择的标准,选取P<0.01的光谱波段。
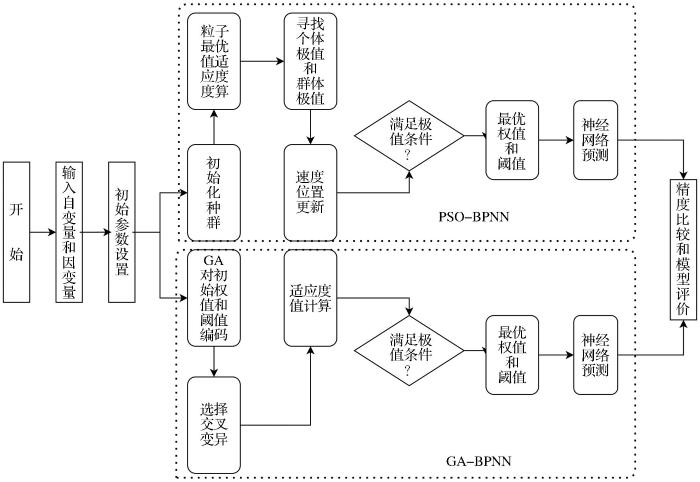
由图3可知,原始光谱(R)与土壤中的Cr、Cu含量的相关系数图中,几个极值点出现在500、1 090、1 400、2 200 nm附近,与土壤反射吸收特征所在的位置相吻合。Cr、Cu与原始光谱相关性的变化趋势来看,其相关性基本呈现出正相关,且两种重金属元素与原始反射光谱相关性曲线的形状、趋势基本一致。Cr、Cu元素实测值在经过一阶微分变换后,曲线相关性在正负之间频率加快,Cr元素相关性较强的波段出现在450、750、1 200、1 500、2 000、2 200 nm附近,Cu元素相关性较强的波段出现在450、600、1 100、1 500、1 900、2 300 nm附近;Cr、Cu元素在经过标准正态变量校正之后,波段650、1 400、1 600、2 300 nm附近相关性较强;Cr、Cu元素经过多元散射校正后,Cr元素相关性较强的波段出现在550、1 350、1 500、2 100、2 300 nm附近,Cr元素相关性较强的波段出现在600、1 200、1 500、2 300 nm附近;Cr、Cu元素实测值在经过对数变换之后,在450、1 650、2 150、2 300 nm波段附近相关性较强。Cr、Cu元素经过多元散射校正、标准正态变量校正、对数变换、一阶微分变换后相关性显著提高,且曲线的趋势和形态不再呈现出单一的变化形式,可以更好地突出土壤中重金属的光谱反射特征。但单一的数学变换对于特征波段的突出还是比较局限,因此采用两种数学变换相组合的形式,以突出更多的光谱信息。将原始光谱经过标准正态变量校正、多元散射校正、对数变换分别与一阶微分相结合变换之后,其相关性相较于单一的数学变换有了明显的提升,频率加快,且正负相关性加大。
图3
图3
Cr、Cu含量与土壤光谱反射率之间相关性
Fig.3
Correlation between Cr and Cu content and soil spectral reflectance
重金属元素与其光谱反射率数据进行相关性分析后可以更好地体现元素的光谱特征,但相关性较强的光谱波段数较多,光谱特征不具代表性。同时,两个元素相关性强的波段之间重叠性较高,不利于后续反演模型的建立,因此需要对这些相关性较强的波段进行特征提取,使得特征波段能够更好地体现光谱信息。
4.2 特征波长提取
经过VISSA-IRIV特征波段提取后,得到Cu、Cr元素光谱反射率极显著的特征波段提取结果分别为表2~3所示。其中,Cu元素在经过FD、MSC、SNV、MSC-FD、SNV-FD及AT-FD变换,所提取出来的特征波段主要出现在2 212、2 280、2 154、2 152、2376 nm附近;Cr元素提取出的特征波段主要在2 436、2 387、2 446、2 163、2 375、2 382 nm附近。提取出的重金属含量与光谱信息之间的关系可以发现,特征波段的提取中相关性并非决定性因素,相关性的高低并不能完全反映光谱信息的多少。因此,本次实验以提取出的特征波段进行模型的建立,并探讨光谱参数的变化是否有利于对于反演模型精度的提高。
表2 基于VISSA-IRIV特征提取Cr元素特征波段
Table 2
| 光谱变化 | 特征波段/nm | 最大相关系数波/nm | 最大相关系数 |
|---|---|---|---|
| R+SG | 1 624、1 626、1 917、2 182、2 184、2 202、2 205、2 264、2 266、2 421、2 422、2 423 | 2 422** | -0.73 |
| SG+FD | 1 649、1 650、1 651、2 164、2 165、2 166、2 310、2 345、2 346、2 362、2 363、2 364、2 365、2 436 | 2 436** | -0.73 |
| SG+MSC | 1 189、1 250、1 253、1 280、1 358、1 371、1 585、1 909、1 940、2 149、2 150、2 152、2 248、 2 304、 2 320、2 323、2 387 | 2 387** | -0.69 |
| SG+SNV | 1 451、1 452、1 495、1 504、1 517、1 527、1 531、1 714、1 755、2 390、2 438、2 446 | 2 446** | -0.70 |
| SG+MSC+FD | 879、1 139、1 178、1 378、1 413、1 418、1 470、1 471、1 503、1 505、1 649、1 969、2 032、2 163、2 167、2 174、2 264 | 2 163** | -0.76 |
| SG+SNV+FD | 878、886、1 036、1 062、1 063、1 064、1 649、1 650、1 651、1 985、2 154、2 344、2 345、2 346、 2 364、2 365、2 366、2 375、2 381 | 2 375** | -0.71 |
表3 基于VISSA-IRIV特征提取Cu元素特征波段
Table 3
| 光谱变化 | 特征波段/nm | 最大相关系数波/nm | 最大相关系数 |
|---|---|---|---|
| R+SG | 1 300、1 361、1 362、1 362、1 363、1 364、1 582、2 144、2 179、2 188、2 276、2 277、2 372 | 2 277** | -0.64 |
| SG+MSC | 1 193、1 194、1 195、1 201、1 202、1 221、2 119、2 160、2 209、2 210、2 212、2 430 | 2 212** | -0.64 |
| SG+SNV | 622、623、1 356、1 357、1 359、1 404、2 193、2 247、2 248、2 249、2 250、2 280、2 282、2 292、2 431 | 2 280** | -0.68 |
| SG+MSC+FD | 818、822、871、1 061、1 329、1 377、1 382、2 154、2 214、2 266、2 375 | 2 154** | -0.66 |
| SG+SNV+FD | 584、787、788、798、822、871、1 061、1 328、1 422、1 876、2 146、2 151、2 152、2 214、2 373 | 2 152** | -0.65 |
| SG+AT+FD | 501、538、819、2 203、2 206、2 213、2 251、2 256、2 372、2 376 | 2 376** | -0.59 |
4.3 模型精度评价
基于特征光谱参数作为自变量(即神经网络的输入层)、土壤重金属含量作为因变量,分别建立 Cr、Cu的偏最小二乘(PLSR)、BP神经网络、粒子群优化BP神经网络(PSO-BPNN)、遗传算法优化BP神经网络(GA-BPNN)反演模型。
4.3.1 评价指标
研究区域的土壤组成、土壤采样操作的正确性、光谱数据的处理、光谱特征选取的方式以及反演模型的选择等因素都会影响土壤重金属光谱反演模型的精度。因此为了对所选取的各种模型及其预测效果进行科学有效的评价,本文采用决定系数(R2)、均方根误差(RMSE)、相对分析误差(RPD),作为模型精度的评价指标。其中R2越接近1、RMSE越小、RPD越大模型精度越高,其模型精度评价指标公式如下:
4.3.2 结果分析
RPD能够较好地体现模型的稳健性,当RPD<2时,模型不能够进行定量预测;当RPD在2.0~2.5之间时,该模型只能作为一个简单的变量预测使用;当RPD的值在2.5~3.0之间时,其结果能够得到很好地预测,并且其值越接近3.0,预测效果越好;当RPD的值>3时,模型为最理想状态。将经过处理之后的土壤光谱数据分别用BPNN模型与PLSR模型进行预测,两个模型的建模结果如图4(a)、图3(b)所示。按照决定系数R2越大、均方根误差RMSE越小,模型的预测效果越好的原则,Cu经过预处理之后R2增大,RMSE减少,模型的预测效果提高。但对于Cr元素,其RMSE在经过预处理之后反而出现提高的现象,因此,这两个模型对于该元素的预测效果并不理想。对于土壤中Cr、Cu的整体反演效果中,BPNN模型预测效果明显优于PLSR模型。但是使用BPNN模型对Cr、Cu反演的结果中,RPD的值在2.0~2.5之间,只能进行简单的预测,若想要提高模型的稳定性,还需要对BPNN模型作进一步的改进。
图4
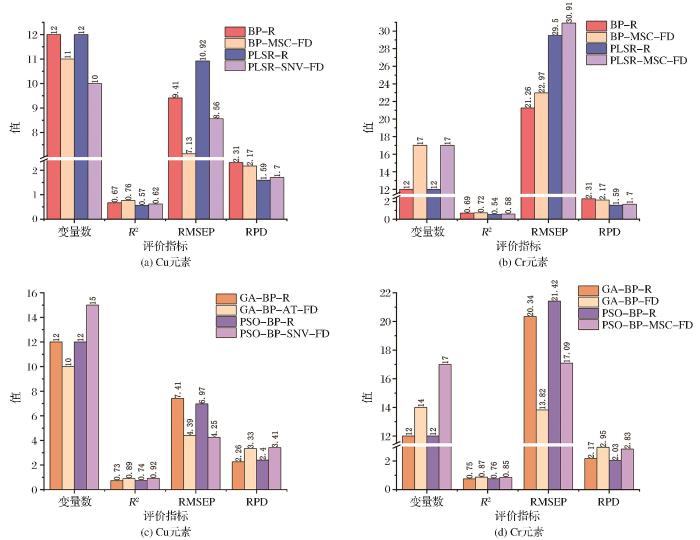
图4
Cr、Cu元素模型预测精度对比
Fig.4
Comparison of model prediction accuracy for Cr and Cu elements
为了解决上述问题,实验使用PSO、GA算法对BPNN模型进行优化,并将BP神经网络训练集的MSE作为适应度函数,获取最优的权值和阈值,再反向输入到BP神经网络构建回归预测模型。两个模型在寻找最优个体时,随着迭代次数增加,适应度都逐渐向最优值接近,并且在达到最优值时,其值趋于稳定,这也表明了预测值与实际值误差趋于稳定。
PSO-BPNN、GA-BPNN模型对于土壤中Cr、Cu元素的预测结果如图4(c)、图4(d)所示,相较于原始光谱,预处理之后的光谱使模型的预测效果显著提高。将多种数学变换及其组合形式的光谱处理结果应用到模型中,提取出效果最好的变换方式。Cr元素仅使用一阶微分变换且用GA-BPNN回归模型预测的R2和RMSE分别为0.87和13.82,较MSC-FD变换且用PSO-BPNN回归模型预测的R2和RMSE使得模型更稳定,能够更好地表征Cr元素的光谱响应信号。同时,GA-BPNN模型对于Cr元素预测结果的相对分析误差(RPD)为2.95,高于PSO-BPNN模型的2.83,模型的预测效果更好。Cu元素使用优化之后的BP神经网络的效果好于仅使用BP神经网络预测结果。从两个优化之后的模型中分别提取出的Cu元素最佳处理方式,结果表明使用SNV-FD光谱变换的PSO-BPNN模型对于Cu元素预测效果最好,R2达到了0.92,RMSE为4.25,同时RPD的值超过3.0,模型的预测效果极好。
经过上述对比之后,得到研究区土壤中Cr、Cu元素的最佳预测模型,分别为FD-GA-BPNN和SNV-FD-PSO-BPNN。为了验证模型的预测效果,将重金属元素的预测结果与实测结果进行对比,如图5所示,横轴代表样本个数,纵轴代表元素含量。图5(a)、图5(b)中分别将Cr元素15个样本、Cu元素14个样本的实测值和模型预测值进行对比,实测值和预测值的折线基本吻合,表明模型的预测结果较好。经过算法优化之后的神经网络相较于线性模型能够更好地表征Cr、Cu元素的响应信号,同时可以在一定程度上减少噪声对于数据建模的影响,并且使用特征波段提取算法能够对光谱数据高效降维,降低了模型复杂度,从而提高了模型的反演精度。
图5
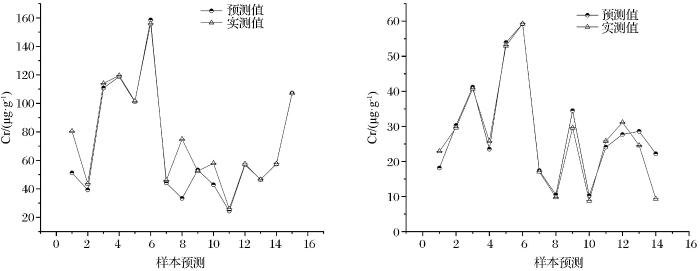
图5
土壤中Cu、Cr元素含量模型检验
Fig.5
Model test for elemental content of Cu and Cr in soils
5 讨 论
本次实验通过对获取的土壤光谱数据进行特征提取,并结合非线性特征的模型算法对土壤中重金属含量定量反演,有效的说明对于高光谱这种非线性数据,使用非线性模型的预测效果更好,模型稳定性更高。这是之前很多的研究中未涉及的,同时有研究表明使用线性模型对非线性数据的特征进行提取效果不佳[9],在本文中得到进一步的体现。
本次研究中由于研究区地形环境等较为复杂,所采集到的样本数据量较少,对于模型的建立有一定的影响。同时模型中对于参数的选取存在指定性,不同的算法中最优参数的选取不同,使得所建立的反演模型对于其他地区是否适用还需要进一步讨论。
6 结 论
实验利用从连州市野外采集的土壤样本,获取的实验室土壤反射率数据对研究区进行土壤重金属含量定量反演,以Cu、Cr元素为研究对象,使用优化算法的BP神经网络模型估算得到了较好的结果。研究得到了以下结论:
(1)对原始光谱数据进行SG平滑、MSC等数据预处理后,有效增强了重金属光谱敏感性,经过处理之后的光谱数据,在模型中进行预测的效果明显强于原始光谱。
(2)将处理之后的光谱数据与土壤重金属含量进行相关分析时发现,原始光谱的相关性呈现出显著相关,而能够将相关性特征突显的数学变换,在处理之后效果并不明显,甚至有下降的趋势。这种现象进一步表明线性变换对于土壤光谱数据的特征提取还有待进一步研究。同时模型使用原始光谱进行反演预测时,模型稳定性差,精度也不高。因此,只是使用相关性的高低作为特征波段提取的条件还不足够。在此基础上,本次实验使用了VISSA-IRIV算法进行特征波段的提取,将更具代表性的波段提取出来,使得模型的稳定性和反演的精度得到提升。
(3)BPNN模型较PLSR模型有更大的反演优势,但模型的稳定性不高,因此采用PSO、GA算法优化并将BP神经网络训练集的MSE作为适应度函数,获取最优的权值和阈值,再反向输入到BP神经网络构建回归预测模型,极大地提升了模型的反演精度,其中土壤中Cr、Cu元素的最佳反演模型组合分别为FD-GA-BPNN(R2=0.87、RMSE=13.82、RPD=2.95)、SNV-FD-PSO-BPNN(R2=0.92、RMSE=4.25、RPD=3.41)。
(4)通过遗传算法和粒子群算法进行优化之后的神经网络模型,模型稳定性得到明显的改善,且模型反演的精度提高,该研究对土壤重金属含量的准确、快速分析提供了一种有效的方法, 对实现土壤重金属污染治理具有重要的现实意义。
参考文献
Application and development of hyperspectral remote sensing technology in the field of soil heavy metal content determination
[J].
高光谱遥感技术在土壤重金属含量测定领域的应用与发展
[J].
Hyperspectral inversion of heavy metal content in urban traffic green space soils
[J].
城市交通绿地土壤重金属含量的高光谱反演
[J].
Hyperspectral inversion modeling of soil heavy metals in Enshi, Hubei
[J].
湖北恩施地区土壤重金属高光谱反演模型研究
[J].
Hyperspectral inversion of Hg content in arable soils by feature variable selection combined with SVM
[J].
特征变量选择结合SVM的耕地土壤Hg含量高光谱反演
[J].
The potential of field spectroscopy for the assessment of sediment properties in river floodplains
[J].
Hyperspectral inversion study of soil chromium content in the black soil region of Northeast China
[J].
东北黑土区土壤铬含量高光谱反演研究
[J].
Hyperspectral-based inversion study of nickel content of heavy metals in soils of iron ore mining areas in Beijing
[J].
基于高光谱的北京铁矿区土壤重金属镍元素含量反演研究
[J].
Hyperspectral visible–near infrared determination of arsenic concentration in soil
[J].
Hyperspectral image feature extraction based on generative adversarial network
[J].
基于生成对抗网络的高光谱图像特征提取
[J].
Hyperspectral sensing of heavy metals in soil and vegetation: Feasibility and challenges
[J].
Study on the distribution characteristics and influencing factors of selenium content in soils of Lianzhou City, a mountainous area in northern Guangdong
[J].
粤北山区连州市土壤硒含量分布特征及影响因素研究
[J].
Determination of six heavy metals in soil by tetraacid microwave ablation-inductively coupled plasma atomic emission spectrometry
[J].
四酸微波消解-电感耦合等离子体原子发射光谱法测定土壤中6种重金属元素
[J].
Variables selection methods in near-infrared spectroscopy
[J].
The potential of Near Infrared Reflectance Spectroscopy (NIRS) for the estimation of agroindustrial compost quality
[J].
Hyperspectral estimation of soil heavy metal copper content based on Partial Least Squares
[J].
基于偏最小二乘的土壤重金属铜含量高光谱估算
[J].
Prediction of SEPA-VISSA-RVM near-infrared spectra for compressive strength of birch with smooth grain
[J].
桦木顺纹抗压强度的SEPA-VISSA-RVM近红外光谱预测
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}